前言
本次来解锁新姿势——CSS字体反爬。
1 | 在解决这个字体反爬的路上,当我以为解决这个反爬手段的时候, |
0x01、分析目标网站
还是同样的手段,打开F12进行选中数字,查看它的标签内容是什么
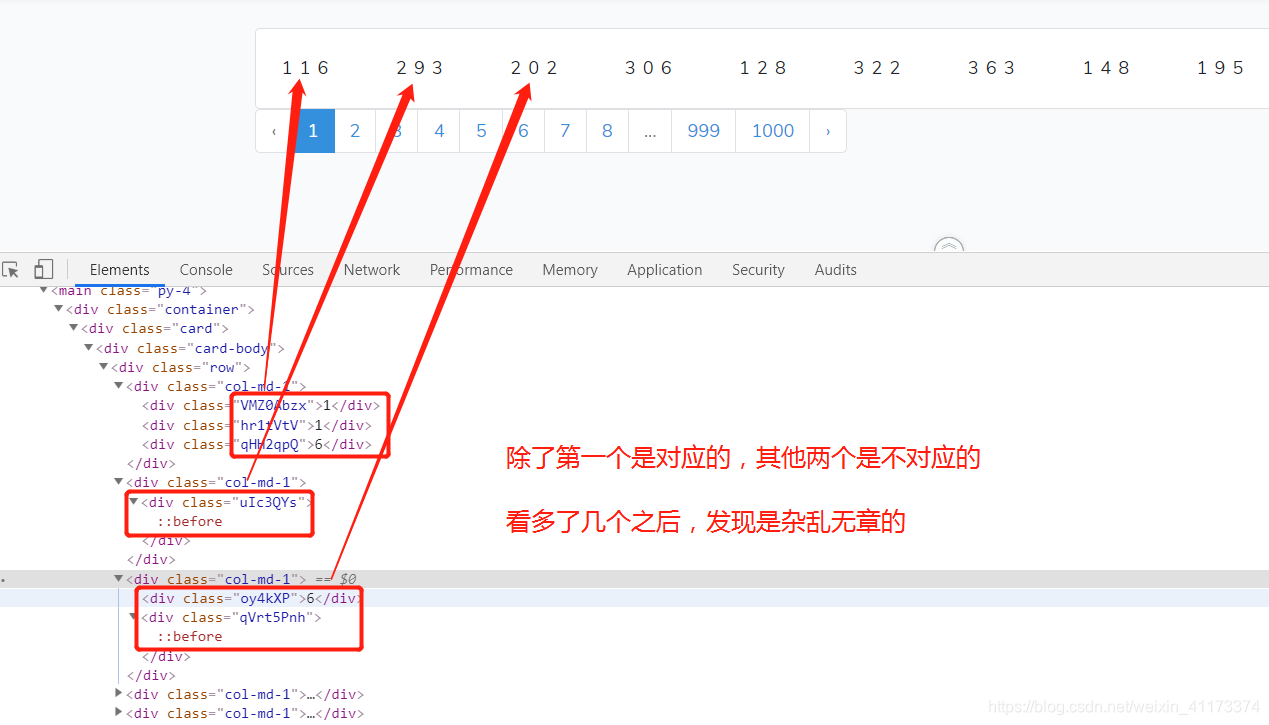
很明显,看了三个标签,只有第一个是对上的,其他两个是对不上的,难道是所有页面都是第一个对上,后面数字都打乱?并不是的,经过多次请求发现,每次都是随机打乱的,打乱的看起来好像没有规则。那我也随便找找,看看有什么突破口不,首先去找id属性去全局搜索,看一下有什么相关内容
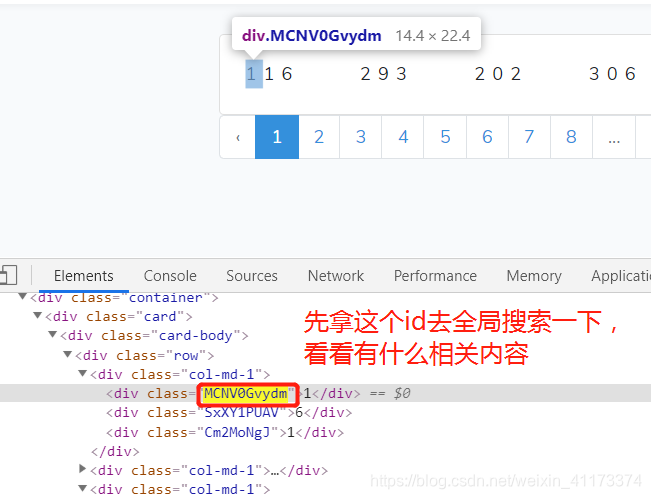
出现关联的数据如下: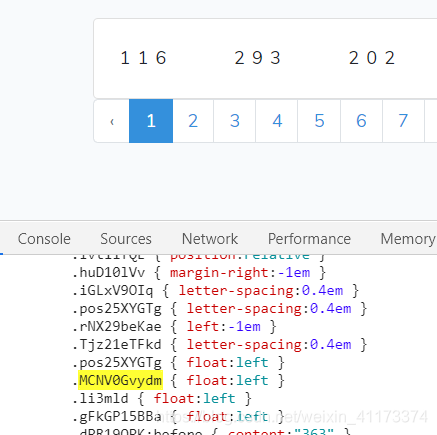
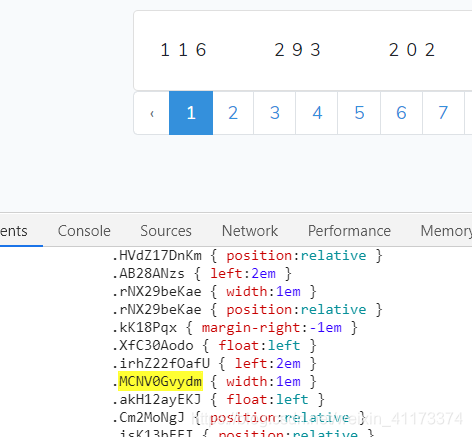
出现的这两个东西,突然不知道是啥,那我就去谷歌一下呗,发现这两个是css知识里面的东西,又涨知识了
Tips:这些属性在文末有提到,可以翻到后面一起对照看
- 竟然没有什么突破口,那我继续搜索多几个看看
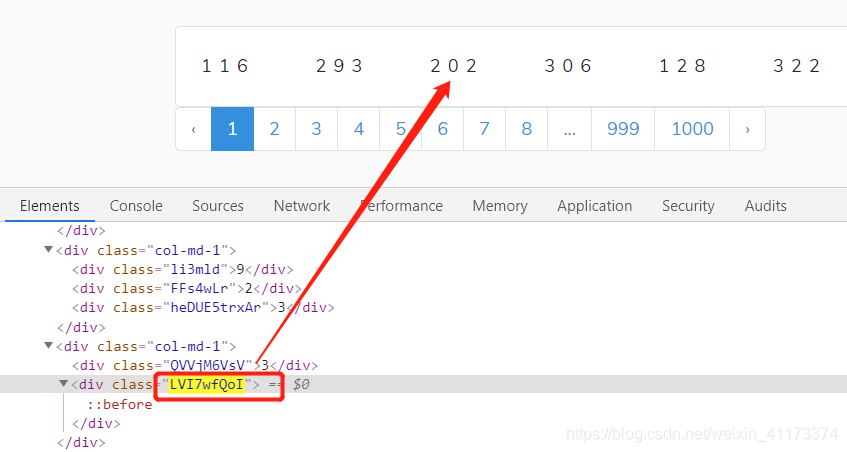

- [x] 看,这个content:”202”不就是我们想要的吗,太爽了,终于找到一点点突破口了,谷歌百度一下这个:before你会发现它是CSS里面的属性
再继续找找其他的数字看看,比如看到这个数字128:
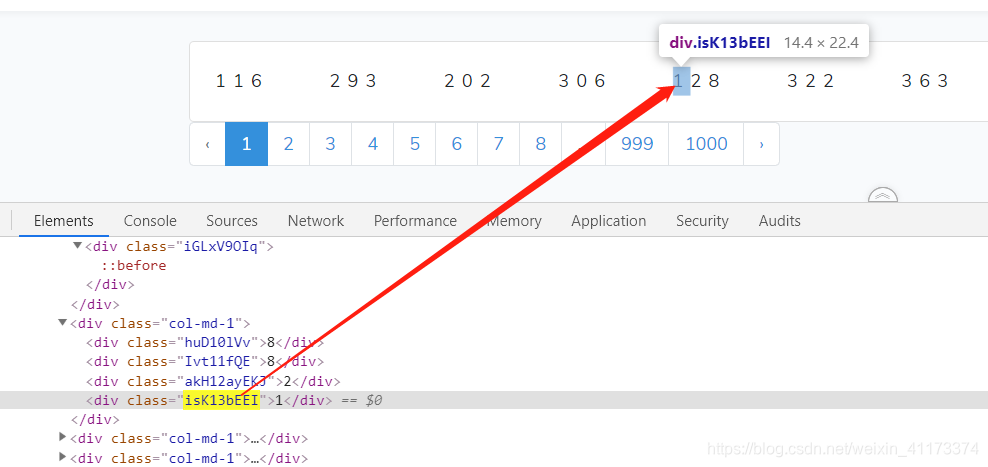
搜索这个属性看看,又发现了两个属性:position、left。position顾名思义就是位置的属性,用relative表示,翻译过来就是相对位置的意思

跟前端展示的综合起来,大概的意思就是:相对的位置,然后left表示偏移的方向及偏移多少,然后最终才是我们肉眼在前端看到的正确位置的数字,那开始造起来呗,just do IT!
0x02、核心代码
(1)、下面代码就是核心判断字体是否是出现偏移或者是before属性的类型
1 | import re |
到此,我==以为==我是用正确的姿势==解决==这种问题了,可惜==并不是!!并不是!!!==
这中间我通过一边下载html源码一边慢慢核对前端展示的数值跟代码返回的是否一样的时候,当我发现有些两位数的数值出现匹配错误的情况,匹配出来是3位数,这到底为什么呢
(2)、下面将继续来看一下到底是为什么这样?
将这种特殊两位数的,匹配出三位数的情况,进行分析,搜索id属性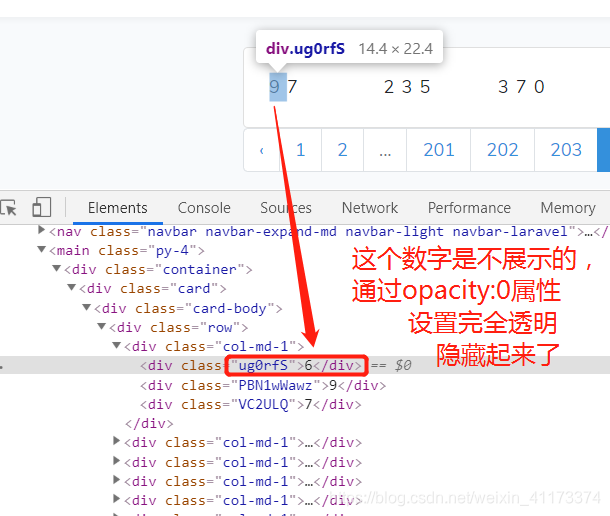
- 这次又发现了一个属性,==opacity属性==,这个翻译过来是“不透明度”的意思,点击我进行了解
查看介绍,大概明白了,html源码可以通过设置元素的透明度,来达到前端肉眼是否看到的效果,如果设置为0则表示完全透明,为1则表示完全不透明
- 下面我通过修改html源码的opacity属性进行剖析,发现设置opacity属性为0和1是得到不同的结果

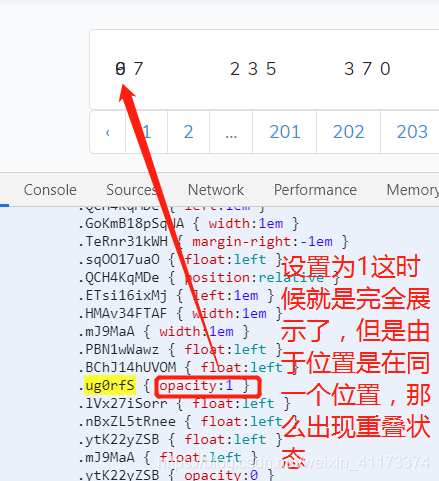
那为什么是重叠的呢?其实刚刚搜索出来的结果还有一个属性,叫==margin-right==,这个属性在CSS里面用来设置边距的,那么我们将原来的属性注释掉或者修改为0看看得到什么结果: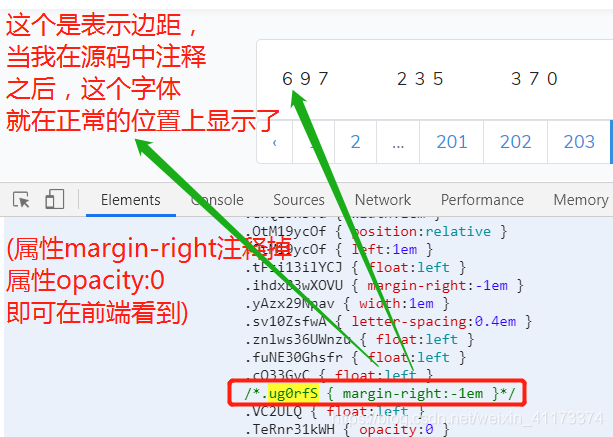
(3)、小结
- [x] 来小结一下前面几个属性
如果不是很明白那些属性,那么去谷歌或者百度一下,看看这些都是代表什么含义
- [x] 来小结一下前面几个属性
| 属性 | 含义 |
|---|---|
| width:2em | 是字体宽度大小。 它是描述相对于应用在当前元素的字体尺寸,所以它也是相对长度单位。一般浏览器字体大小默认为16px,则2em == 32px;详解 |
| float:left | 把图像向左浮动,详解 |
| :before { content “202” } | :before 选择器向选定的元素前插入内容,使用content 属性来指定要插入的内容,详解 |
| left:-2em | 把当前元素向右移-2em单位,即等于向左移2em单位,详解 |
| opacity | 透明度属性,取值范围为0-1,。为0表示完全透明,为1表示完全不透明,详解 |
| margin | 外边距,详解 |
总结一下这种CSS反爬手段解决顺序:
- 首先判断元素是否透明:当我们遇到存在opacity属性为0的就是可以忽略它,不是0的就继续判断后面的
- 判断其大致规律性,如下(根据==不同网站==来设置,本文教程的大致规律性不一定符合所有CSS反爬手段的网站,需要==适当调整一下==):
div标签长度为3的可能:乱序的,或者顺序的,或者第一个标签是透明的,真正展示的应该是两位数字的; div标签长度为4的可能:有一个标签是不展示的,剩下三个标签是乱序的或者是顺序的(这个使用属于长度为3的情况去判断) div标签长度为2的可能:目前发现的,只有包含:before的div标签是可用的,另外一个标签的内容是可以忽略的
由于本文教程是,最后才发现opacity属性的,所以我代码里面并不是第一步判断opacity属性,但是我在总结的时候,个人推荐,先判断opacity属性,如果为透明的话,都可以直接跳过那个元素了
(4)、最终代码
1 | #!/usr/bin/python3 |
至此本文教程写完了,希望能够帮助到各位在爬虫路上的小伙伴们,觉得不错点个赞呗
感谢认真读完这篇教程的您
先别走呗,这里有可能有你需要的干货文章: